
Concepts You Have to Know for Data Science Interviews — Part IV. Random Forest
Most frequently asked questions in data scientist interviews


Most frequently asked questions in data scientist interviews
This is the 4th article in the interview series. I’m hoping this series will function as a centralized starting point for aspiring data scientists in terms of interview preparation. So far, we have talked about the following concepts:
In this article, I want to continue the journey down the ML lane and talk about advanced supervised learning models. More specifically, I will be focusing on Random Forest since it is probably the most commonly used and commonly asked in DS interviews among the more complicated/advanced ML models. In fact, I was asked about Random Forest in my interview with McKinsey as a data scientist; knowing how to explain the algorithm on the high level and intuitively will definitely help you stand out from the rest of the interviewees if there’s a modeling component in your interviews.
What is Random Forest
We talked about CART model in the previous article. As a reminder, CART stands for Classification and Regression Tree; and Random Forest, well, is a forest. The descriptive naming convention reveals the clear relationship between the two — Random Forest consists multiple decision trees.
Random forest is an ensemble method (ensemble methods is a category of ML methods that combines multiple learning algorithms to obtain better results, achieving that 1+1>2 effect), utilizing multiple trees to avoid overfitting (decision trees are prone to overfit). Imagine each tree in the forest casting a vote and having a say in the final decision of the whole model; the final decision/prediction is achieved through the forest taking the majority vote.
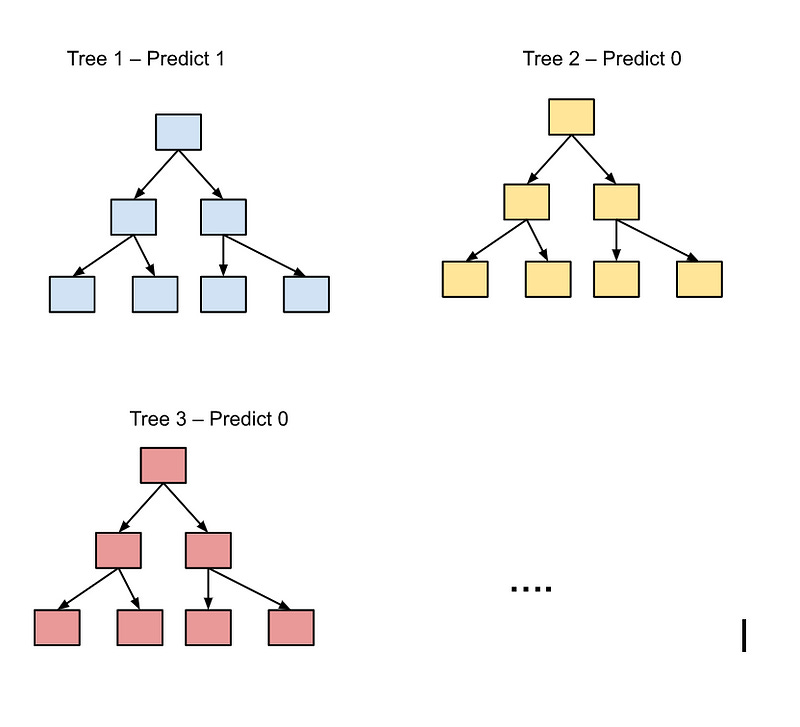
In order to avoid overfitting, the trees shouldn’t be correlated. How does the model avoid trees being correlated? You might ask. Random Forest makes sure of that by doing two things — when building each tree, randomly selecting a subset of training samples, and randomly selecting a subset of features. This “random subsetting” is often used in ensemble models and is commonly referred as “bagging” and is often used to reduce variance in trained models.
A little digression here since we are talking about “bagging”. “Boosting” is another method commonly used in ML models; in fact, Gradient Boosted Decision Trees is a high-performing cousin in the decision-tree family. I’m mentioning this because “Bagging” and “boosting” are often compared; I was asked in different interviews about the differences between them. What’s special about “boosting” is it can improve weak learners. Different from “bagging”, which builds trees in parallel and separately, the “boosting” process builds trees sequentially; so each tree can “learn” from the previous one’s mistakes and improve.
There are a lot of detailed explanations about “boosting” on Medium so I won’t go into any technicalities here. But it’s worth noting that due to this “sequential” nature, “boosting” algorithms train more slowly and are more prone to overfitting comparing to their “bagging” counterparts.
Back to Random Forest. If you remember what we talked about in the previous article, CART’s biggest advantage is arguably its interpretability. Even though random forest is usually an improvement from CART in terms of performance (especially on test sets since it is less prone to overfit), it sacrifices interpretability to some extend in the process. As the number of trees grows, it will be harder and harder to plot each tree and see the features they used in splitting the data; thus it becomes harder to understand exactly how each tree was built. But it’s still possible to generate a plot for feature importance (across the trees in the forest). Most random forest packages come with such a plot that’s easy to access.
How are these tested and what to watch out for
I have already went through in the previous post about how ML concepts are usually tested and the most important things to remember when you answer ML modeling questions. Click to that post (linked below) if you want to read more.
Concepts You Have to Know for Data Science Interviews — Part III. Basic Supervised Learning Models
Most frequently asked questions in data scientist interviews for modelingtowardsdatascience.com
The only thing to add about random forest, or any complicated ML algorithms in general, is it’s important to be able to explain the algorithms in layman terms. What I mean by that is the interviewers usually are interested in testing your understanding of the algorithm, but are not looking for a memorized version of the wikipedia page of it.
Little tip at the end, the best audience for practicing your intuitive explanation of ML algorithms is friends who are not in the analytics field; you can quickly tell if your description of the algorithm is making any sense.
Interested in reading more about data science career tips? I might have something for you:
5 Lessons McKinsey Taught Me That Will Make You a Better Data Scientist
towardsdatascience.com
Why I Left McKinsey as a Data Scientist
Things you should consider before starting as a data science consultanttowardsdatascience.com
The Ultimate Interview Prep Guide for Data Scientists and Data Analysts
What helped me interview successfully with FANG as well as unicornstowardsdatascience.com